Koshima Satija
Co-founder & COO, Flexprice

If you've ever compared Voice AI pricing across providers, you've probably noticed that almost everyone advertises a per-minute rate. Deepgram, AssemblyAI, Vapi, and Retell also charge per minute.
Looks like everyone here is speaking the same language, but actually, they’re not.
The "minute" in Voice AI is one of the most inconsistent units of measurement. How a provider defines, measures, rounds, and bills a minute varies dramatically, and those differences compound into significant cost gaps at scale.
This blog does a forensic breakdown of how different Voice AI companies actually calculate a minute, why it matters for your billing infrastructure, and what the downstream impact looks like for orchestration platforms consuming multiple APIs.
What is the per minute pricing?
Per minute pricing is exactly what it sounds like. You pay a fixed rate for every minute of usage consumed, but in Voice AI, that rate typically covers one or more layers of the stack, like speech recognition, language model processing, voice synthesis, or telephony.
It's the dominant pricing model across Voice AI for a simple reason: minutes map naturally to how people think about phone calls. A sales team running 10,000 outbound calls doesn't want to think in tokens, characters, and WebSocket connections. They want to know what each minute of AI conversation costs them.
But here's where it gets deceptive. The word minute suggests standardization, like 60 seconds is 60 seconds everywhere. In practice, a billable minute is a construct, and every provider builds that construct differently:
So when you see two providers both advertising $0.05/min, you're not comparing the same thing. You're comparing two different definitions of what a minute even is, wrapped in identical packaging.
Where the inconsistency starts: STT
The per-minute definition problem originates at the infrastructure layer, specifically with Speech-to-Text (STT) providers. This is where audio becomes data, and how usage is measured at STT ends up shaping your entire billing.
See how three major STT providers can handle the same 47-second audio file in different ways:
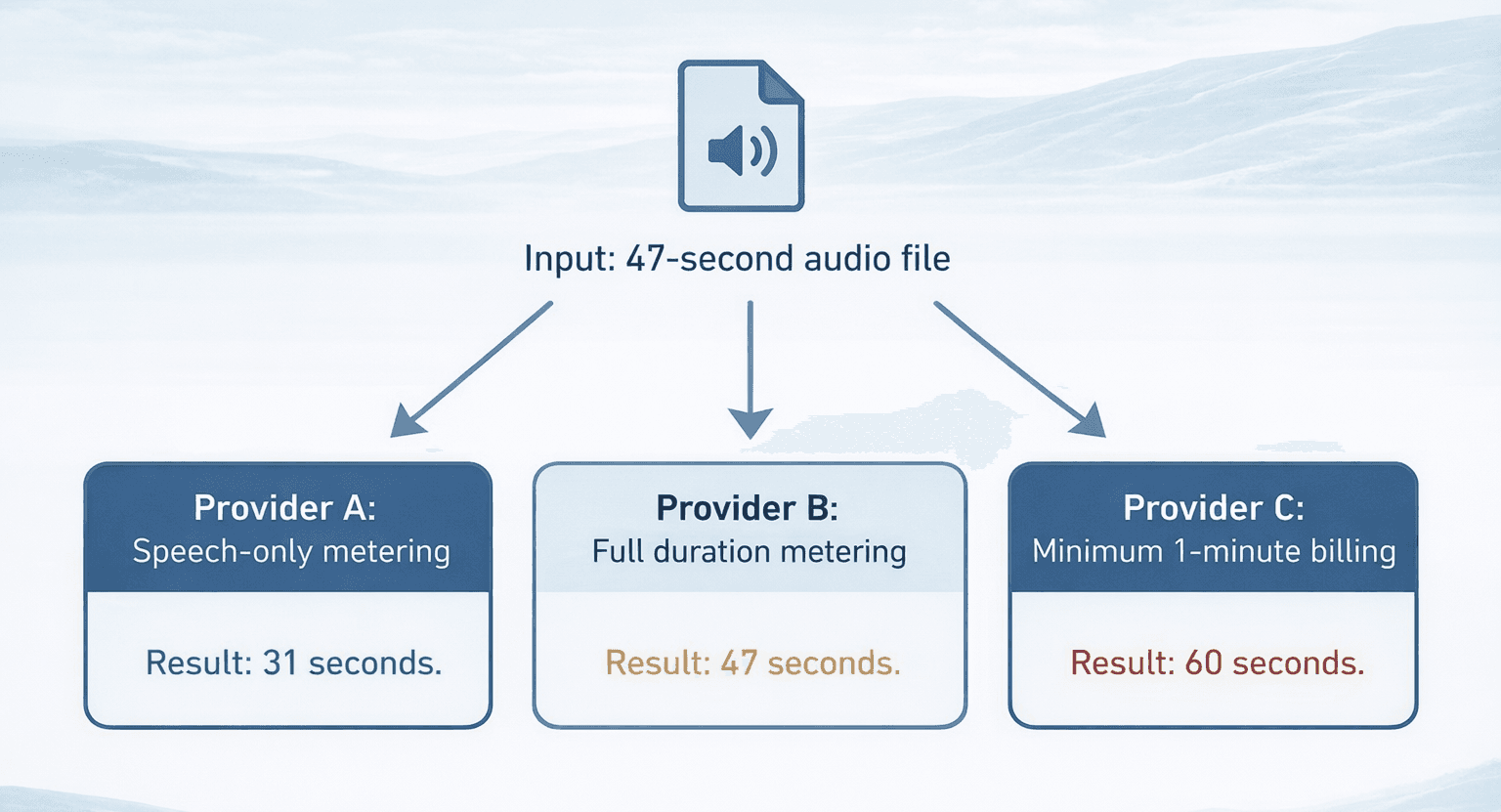
Provider A
Before metering, the audio is analyzed for non-speech segments like silence, background noise, hold music, and only the portions containing actual speech are counted. That 47-second file might be metered as 31 seconds of billable audio.
Provider B
The entire duration of the audio file is metered, including the silence. The same file is billed at 47 seconds.
Provider C
Regardless of actual duration, any file under 60 seconds is billed as one full minute. The file will cost the same if it is a 59-second file or a 3-second file.
Same input. Three different costs. And we haven't even talked about how those seconds get turned into minutes on your invoice.
The rounding problem
Rounding rules are where small differences become large money at scale. There are four common approaches to rounding in Voice AI billing:
Round up to the nearest minute
Every call, no matter how short, is billed as at least one minute. A 10-second test call costs the same as a 58-second call. This is common in telephony-native providers.
Round up to the nearest second
More granular than per-minute rounding. A 47.3-second call is billed as 48 seconds. This feels precise, but the rounding still adds up across millions of calls.
Round to the nearest 6-second increment
Some providers don’t charge exact seconds. Instead, they bill in small chunks, like 6 or 10 seconds. So even if your call is shorter, it gets rounded up to the next chunk, like a 43-second call is billed as 48 seconds, and a 47-second call is billed as 48 seconds
Exact duration with sub-second precision
The most granular approach. Here, a 47.3-second call is billed at exactly 47.3 seconds. This is rare in practice but increasingly common with API-native providers.
Now, consider what happens when you process 100,000 calls per month with an average duration of 45 seconds.
With per-minute rounding, every call is billed as 1 minute. Your bill: 100,000 minutes.
With per-second rounding, assuming the same 45-second average, your bill: 75,000 minutes.
That's around 33% difference for the same actual usage. The gap isn't in the rate. It's in the definition of the unit.
Streaming vs. batch: two different meters
The definition of a minute also changes depending on how the audio is processed.
In batch processing, you send an audio file, it gets transcribed, and you're billed for the duration of the file. The metering is straightforward: file duration equals billable time.
Streaming processing works in real time; here, audio is sent to the STT provider as a continuous stream via WebSocket, and the connection stays open for the entire conversation. The part where it gets tricky is whether you billed for the duration of the audio or the duration of the connection.
If a customer's AI agent has a 3-minute conversation, but the WebSocket connection stays open for 3 minutes and 12 seconds because of setup latency, final processing, and connection teardown, the difference is 12 seconds. At scale, those extra seconds add up, and you lose your margin.
Here are examples of how some providers bill:
From the first audio byte to the last audio byte
Others bill from connection open to connection close.
And some bill only for segments where audio was actively flowing, excluding gaps.
For orchestration platforms that manage thousands of simultaneous calls, the definition of when a billable minute starts and stops isn't academic; it's a direct margin impact.
The multichannel problem
Many Voice AI calls involve multiple audio channels, but a standard phone call has two channels: the caller and the AI agent. Some contact center implementations can have more than two, like the customer, the AI, and a human supervisor.
Providers handle multichannel audio in three different ways:
Bill per channel
A stereo (2-channel) call that lasts 5 minutes is billed as 10 minutes. This is common with providers that offer per-channel transcription for diarization purposes.
Bill per call duration
The same stereo call is billed as 5 minutes regardless of the number of channels. The provider mixes or processes channels internally.
Bill per channel, but discount
The primary channel is billed at the full rate, and additional channels get a reduced rate 50% or less. A 5-minute stereo call might be billed as 7.5 minutes.
If your platform advertises a per-minute price to customers, you need to decide: do you bill your customer for the call duration or the processing duration? If you bill for call duration but your STT provider bills per channel, your margin gets squeezed on every multichannel call.
The downstream impact on orchestration platforms
For infrastructure providers (STT, TTS, LLM), per-minute inconsistency is a known cost of doing business. They set their own definitions, and their customers adapt.
But for orchestration platforms, the companies that stitch together multiple providers into a single Voice AI product, these inconsistencies create a much bigger problem.
An orchestration platform consuming Deepgram for STT, OpenAI for the LLM, and ElevenLabs for TTS is running three different meters simultaneously for every call:
Deepgram measures audio duration in seconds, with silence handling.
OpenAI meters LLM processing in tokens.
ElevenLabs meters synthesized speech in characters.
The platform then needs to present a single, unified per-minute price to its end customer. That per-minute rate is an abstraction over three fundamentally different billing units.
The translation layer between provider metering and customer billing is where orchestration platforms either build margin or lose it. If your internal cost calculation assumes Deepgram will meter 45 seconds for a call, but Deepgram actually meters 60 seconds because it rounds up, your margin on that call is lower than your model predicts.
Scale that across thousands of calls per day, and the metering assumptions in your billing system become one of your most important financial variables.
How the definition gap affects customer trust
The per-minute inconsistency doesn't just create internal cost problems. It also creates customer trust problems.
When a customer runs their own stopwatch on a call and sees 2 minutes and 14 seconds, but your invoice shows 3 minutes, they feel overcharged. It doesn't matter that the difference is explained by rounding rules, connection setup time, and multichannel processing. From the customer's perspective, the numbers don't add up.
This is especially acute in Voice AI because the end users' businesses deploying AI agents are often metering-aware. They're tracking their own usage internally. They have dashboards showing call durations. When those numbers don't match your invoice, the first instinct is to suspect your billing, not question the definition of a minute.
The most transparent Voice AI platforms address this directly. They publish their metering methodology: how they define a billable minute, whether silence is included, what rounding rules they use, and how multi-channel calls are handled. This doesn't eliminate questions, but it provides a clear vision to support teams when customers ask.
Some platforms go even further and show both the raw duration and the billable duration on every invoice line item. This level of transparency requires more sophisticated billing infrastructure, but it dramatically reduces billing-related support tickets and builds long-term customer trust.
The provider switching dilemma
There's one more dimension to the per-minute problem that's worth addressing: what happens when you switch providers?
The Voice AI infrastructure market is moving fast
New STT models launch every few months
TTS quality keeps improving
Pricing keeps changing
Most platforms will switch at least one provider in their stack within the first 18 months.
When you switch from Provider A, which strips silence and bills per second, to Provider B, who includes silence and rounds to the nearest 6-second increment, your internal cost per call changes, even if Provider B's listed rate is lower.
If your billing system hardcodes assumptions about how the upstream provider meters, a provider switch becomes a billing migration. You need to re-model your margins, potentially update customer pricing, and definitely recalibrate your reconciliation logic.
The alternative is building a metering abstraction layer from the start, where your system captures raw events, the provider adapter translates them into your internal unit, and your pricing engine operates on the internal unit. Provider switches happen at the adapter layer without touching pricing or invoicing.
This is more work upfront, but it's the difference between a provider switch taking a day versus a month.
What this means for your billing infrastructure
If you are basically building in the Voice AI space, whether at the infrastructure layer or the orchestration layer, the per-minute inconsistency creates concrete billing requirements:
Track raw usage independently of pricing
Your metering system should capture the actual duration, the provider-reported duration, and the billable duration as three separate fields. This gives you the audit trail you need when the numbers don't match.
Don't assume minutes are fungible
A minute of STT, a minute of telephony, and a minute of TTS are different cost events, even if they happen simultaneously during the same call. Your billing system needs to track them independently.
Model your rounding impact
Before committing to a provider, calculate the rounding cost at your expected volume. The difference between per-second and per-minute rounding at 100K calls/month can be tens of thousands of dollars annually.
Build provider-agnostic metering
When you switch from one STT provider to another, and you will eventually because the market is moving fast, but your customer-facing billing shouldn't change. The metering translation layer needs to normalize provider-specific units into your own billing metric.
Reconcile provider bills against internal metering
If your system says you consumed 50,000 minutes of Deepgram, and Deepgram's invoice says 54,000, you need to understand the gap. Most of the time, it's rounding. Sometimes, it's a metering bug. Either way, your billing system should flag the discrepancy automatically.
The real takeaway
The per-minute rate is a number on a pricing page. The per-minute definition is a billing architecture decision that affects every invoice, every margin calculation, and every provider reconciliation.
When two Voice AI companies both charge $0.08 per minute, they might be measuring completely different things. One strips silence, bills per second, and counts mono audio. The other includes silence, rounds up per minute, and bills stereo channels separately. The cost difference on the same call could be 2x or more.
The minute isn't the problem. The problem is that your billing system assumes all minutes are equal, which they're not.
And the companies that win here are the ones whose billing systems can track real usage, clean it up, and catch mismatches so their margins don’t drift as they grow.
Why do two voice AI providers with the same per-minute rate produce different bills?
How does per-minute rounding impact voice AI costs at scale?
Does streaming voice AI cost more than batch processing, and why?
How do multichannel calls affect voice AI billing?
What billing infrastructure prevents margin drift from per-minute metering inconsistencies?