Ayush Parchure
Content Writer, Flexprice

When building with LLMs, tokens quickly become your core unit of consumption. At first, it seems quite easy; more tokens mean higher model spending.
But as usage increases, margins begin to shrink. A small group of heavy users can consume far more compute than expected, while your pricing model remains tied to seats or feature access.
And that’s when it becomes clear that without structured LLM token metering, you lose control over how usage turns into revenue.
This guide explains how to meter LLM token usage for billing in a way that makes consumption traceable, aligns it with pricing models, and protects your margins as usage scales.
TL;DR
LLM tokens are the core unit of consumption that directly links AI usage, cost, and revenue.
Without proper token metering, heavy users can quietly consume large amounts of compute and shrink margins.
Token usage should be captured as structured events immediately after each model call.
Teams commonly meter tokens through SDK tracking, observability pipelines, gateways, or event-stream architectures.
Accurate metering requires tracking both input and output tokens, not just the generated output.
Token events should include metadata like customer, feature, model, and environment for correct attribution.
Aggregation measures total usage while rating converts that usage into billable charges.
Credit wallets and hybrid pricing models help monetize token consumption more flexibly.
Platforms like Flexprice turn token events into real-time billing, pricing, and invoicing infrastructure.
Why metering LLM tokens matters now
In 2026, businesses need to keep track of their Large Language Model (LLM) tokens because tokens are no longer just a technical unit; they are the currency of AI operations.
As AI applications move from simple chatbots to more complex, agentic, and self-driving workflows, tracking tokens is important for keeping costs in check, predicting them, and controlling them.
The hidden costs of untracked tokens
When you rely on LLMs without tracking token usage across workloads, you pay more than the sticker price for each token. Untracked tokens add hidden costs that eat away at profit and slow growth. They often don't show up until it's too late.
In practice, teams often see patterns like:
Bill spikes happen without any clear cause. A new feature, bigger context windows, or small changes to prompts can cause big token increases that aren't immediately visible in dashboards.
Without tracking usage, heavy users can quietly consume 30–50% of all tokens, lowering the average margin even though surface metrics look fine.
Pricing decisions remain guesswork. If you don’t know where tokens are actually spent, you can’t price features or tiers in a way that matches cost
Key benefits of metering LLM tokens
Once you start tracking tokens properly, the operational and financial advantages become clear.
Cost control and margin protection
LLM providers charge for each input and output token. With a structured token measurement, you can see :
Track real-time spending at the customer, feature, or user level.
Prevent unexpected bills with alerts and usage limits.
Spot inefficient prompts or workflows that use too many tokens.
Calculate the true cost per task (e.g., per ticket, per report, per workflow).
Performance and latency optimization
Output tokens are created one after the other. More tokens usually lead to longer response times. Measuring usage allows you to:
Find prompts that result in unnecessarily long responses.
Monitor Time to First Token (TTFT) and total generation time.
Recognize delays caused by flows that use too many tokens.
Token visibility improves both cost control and user experience.
Observability and debugging
With the help of this, you can:
Detect endless loops in automated workflows.
Spot sudden changes in usage in real time.
Examine token-level details to understand long or off-target responses.
Operational efficiency
Token data helps you make better infrastructure choices.
Identify repeated queries and set up caching.
Send simpler queries to smaller, cheaper models.
Reserve high-cost models only for complex tasks.
Governance and usage control
Without measuring, enforcement reacts to problems after they occur. With measurement, you can:
Set usage limits for each user or team.
Spot unusual usage patterns.
Prevent one workflow or customer from using up the entire budget.
What exactly should you meter?
Most teams say they track tokens. In practice, they only track part of the picture.
If you want billing accuracy and margin control, you need to measure both direct model tokens and the non-token actions that quietly add to costs.
Raw model tokens
Begin with the tokens your model actually processes, not just what your UI sends.
Prompt tokens
Everything you send to the model, like user input, system instructions, injected context, and RAG results. Long system prompts and verbose retrieval results add up quickly.
Completion tokens
Everything the model generates. These directly affect both cost and latency. If responses drift from 300 tokens to 1,200 tokens, your unit economics change fast.
Cached tokens
Some providers discount repeated context. If you’re not separating cached vs non-cached tokens, you can’t measure real savings.
System + hidden prompt overhead
Frameworks often inject hidden instructions. Agent libraries append tool schemas. RAG systems add unseen context. If you only meter user input, you’re missing the real total.
Non-token cost drivers
This is where most teams lose visibility. You may price on tokens, but infrastructure cost is broader than that.
Tool calls
Each function call may trigger API requests, database writes, or external services. These add cost even if token usage looks stable.
Retrieval augmentation
Every similarity search hits your vector store. At scale, high-frequency retrieval can materially increase infrastructure spend.
Embedding generation
Every document indexed requires embedding tokens. If you’re re-embedding frequently, ingestion cost grows quietly in the background.
Multi-step chains or agents
One user action can trigger 10-20 model calls. If you only meter the final response, you undercount total consumption.
Background retries and error handling
Failed calls, retries, and timeout loops still consume tokens. In production systems, these are not rare.
How to meter LLM token usage for billing
Token metering is not just about reading a number from an API response, Its more about deciding where usage is captured, how it’s structured, and how reliably it flows into billing
"The biggest mistake I see AI teams make is treating token metering as an afterthought. They'll ship a product, start getting usage, and then try to bolt on billing later by parsing API logs or running batch jobs at the end of the day. By that point, you've already lost data, introduced discrepancies, and created a gap between what the customer actually consumed and what you're charging them for. Metering needs to be a first-class concern in your infrastructure from day one, not something you duct-tape together once revenue is on the line." - Manish Choudhary, Cofounder and CEO, Flexprice
Here are the four implementation approaches that will help you understand how teams actually use this in production
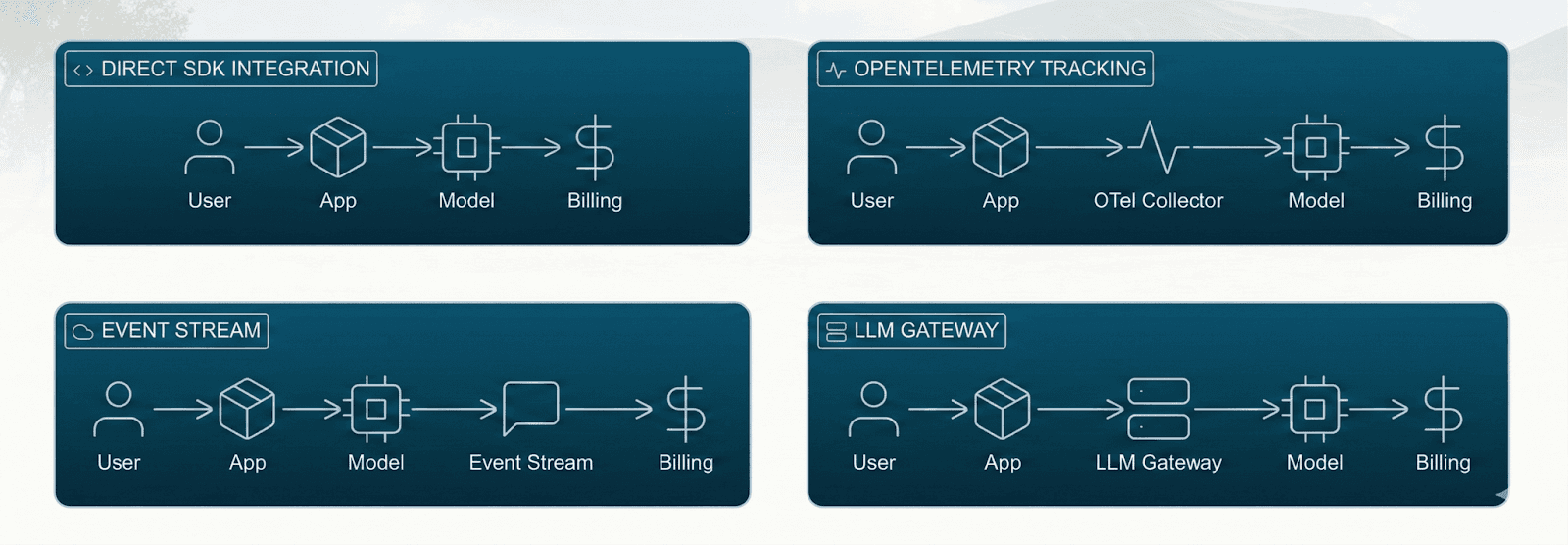
Direct SDK integration
This is the simplest one among the other; here, you can capture usage immediately after each model is called and then push it directly into the billing
After each model call completes, extract the usage metadata directly from the response. Most providers return prompt tokens, completion tokens, and total tokens.
Estimating tokens separately introduces drift, especially once system prompts or hidden context get involved.
Now, once you get the counts, turn them into a structured usage event, like:
customer_id
feature or workflow name
model
prompt and completion tokens
timestamp
Attribution matters more than you think. If you don’t attach usage to a customer and feature at this stage, reporting becomes messy later.
Send the usage event to your billing system immediately after the call succeeds. Real-time or near-real-time reporting lets you enforce quotas, maintain accurate credit balances, and catch anomalies early. Month-end aggregation works for small volumes, but it hides problems until they’ve already grown.
One more thing that you should handle carefully is retries. Without idempotency keys and deduplication logic, you will double-count usage. Every model request should carry a unique identifier so billing can safely ignore duplicates.
This approach works well when one user action maps cleanly to one model call. Once you introduce agents or background workflows, it starts to strain.
Open telemetry-based tracking
If you’re already using distributed tracing, you don’t need to bolt on something completely new. You can extend what you have.
When a model call completes, attach the token usage to the active trace span. Add prompt tokens and completion tokens as attributes, the same way you’d attach latency or error metadata. Now, token usage lives inside the same trace as the rest of the request.
From there, export those traces and metrics to your observability stack, tools like Datadog, Grafana, or Honeycomb. That gives your engineering team visibility into cost alongside performance. You’re not just seeing latency and failures; you’re seeing what each request actually costs in tokens.
But telemetry isn’t billing.
At this point, you’ve collected token data. You haven’t turned it into revenue. To make that leap, you still need:
A pricing layer
Aggregation logic
Customer-level attribution
You have to group usage correctly, apply the right pricing rules, and map everything back to the right customer or account.
This is the transformation step, where teams usually underestimate the complexity. Observability tools are great at measuring and visualizing usage. But they are not billing systems. If you rely on them alone, you’ll still need a separate pricing and aggregation layer to convert telemetry into something you can actually invoice.
LLM gateway approach
As your systems start to grow, you can see LLM calls popping up everywhere, one service here, another background worker there, maybe an agent loop somewhere else, you may not know. That’s when most teams stop calling the model provider directly from each service and put a gateway in the middle.
Now, every LLM call flows through one central service.
Instead of five microservices each talking to the provider in their own way, they all go through the same door. That single gateway becomes your control point.
Because every request passes through it, you only need to capture token usage once. The gateway reads the usage metadata from the model response and emits a clean, standardized usage event.
This helps avoid duplication and guesswork.
Without a gateway, five different teams might log usage in five slightly different formats. Over time, that turns into reporting inconsistencies and billing headaches.
With a gateway, you define one event schema and enforce it everywhere. Every service speaks the same usage language.
There’s another advantage of using this approach: the gateway sees the request before it executes. That means you can:
Check credit balances
Enforce usage limits
Block execution if needed
Instead of discovering overages at invoice time, you control usage in real time.
Event stream architecture
As your usage grows, synchronous logging starts to feel fragile. One timeout, one retry, one partial failure, and now you’re not sure whether usage was recorded correctly.
That’s where an event stream architecture starts to make sense. Instead of trying to update billing directly, it enables you emit immutable usage events.
Every time something happens, a model call completes, an agent finishes a run, and you publish a single, append-only event. That event typically includes:
event_id
customer_id
meter
tokens
relevant metadata
Once emitted, that event gets pushed to your message bus (Kafka, Pub/Sub, etc.). From there, your billing engine consumes those events asynchronously.
Now, billing isn’t sitting in the hot path of your application. It processes usage in the background, at its own pace.
This unlocks a few essential properties like :
Idempotency:
If the same event is delivered twice, you can safely ignore duplicates using event_id.
Replayability:
If pricing logic changes or something breaks, you can replay past events and recompute bills.
Scalability:
As usage increases, you scale consumers without touching your core application.
Instead of tightly coupling product logic to billing logic, you can separate them cleanly. Your product needs to emit facts, and your billing system should interpret them. That's what makes the system resilient as you scale.
How Flexprice meters LLM token usage for billing
Flexprice is an enterprise-grade billing infrastructure designed for usage-based and credit-based pricing. AI products can meter LLM token usage by sending token consumption as usage events, which Flexprice aggregates, prices, and bills in real time.
Token metering as a usage metric
Flexprice treats tokens as a custom usage metric. AI products can define a metered feature such as model usage and send token consumption as usage events. This means the tokens your models process become the billing signal, similar to how other products meter API calls, storage, or compute hours.
Both input and output tokens count because that is how most LLM providers price their services.
Flexprice does not calculate token counts itself. The token usage is already known by your application after the model call completes. Your backend or client captures the usage metadata returned by the provider and sends it to Flexprice as part of a usage event.
Your application sends token usage as structured usage events
Events typically include fields such as tokens_in, tokens_out, or total_tokens, along with identifiers like customer_id, feature, or model. These fields are defined by your product’s instrumentation.
The billing system records these events as metered consumption
Each event is associated with a customer and a pricing meter
Once Flexprice receives the event, it measures the usage and applies the pricing logic defined in your billing configuration. Tokens become a first-class billing unit inside the system rather than something developers manually summarize later.
This helps in removing a common operational problem. Many teams initially store token usage in logs or analytics tools and try to reconstruct billing data later. That approach requires reconciliation, backfills, and manual aggregation. By treating tokens as a metered unit from the start, your usage flows directly into billing without an extra translation step.
Event ingestion
Flexprice receives token usage through structured usage events that your application emits in real time. Each event represents a unit of consumption that the billing engine can meter and price.
Instead of reconstructing usage later from logs or analytics pipelines, your system sends the data as it happens. This ensures billing always reflects actual activity inside the product.
Each event typically includes a set of fields that describe both the usage and the context in which it happened.
Token counts
These fields capture the actual model usage. Input tokens represent the prompt and context sent to the model, while output tokens represent the generated response. Together, they define the total consumption that will be billed.
Customer or tenant ID
This helps in identifying which account generated the usage. The billing system uses this field to attribute every event to the correct customer, workspace, or tenant so that usage aggregates correctly at the account level.
Plan or subscription reference
This links the event to the active pricing plan. It allows the billing system to apply the correct pricing rules, quotas, or credit balances associated with that customer’s subscription.
Feature tag
Feature tags help categorize usage within the product. This makes it possible to price different product features separately or analyze which parts of the product drive the most token consumption.
Model name
Different models often have different cost structures. Including the model name ensures the billing system can apply model-specific pricing or adjust rates if underlying provider costs change.
Additional metadata used for pricing logic
Extra fields such as region, environment, agent type, or request type can also be attached. These attributes allow pricing rules to reference more context if needed.
Flexprice does not infer token usage from requests or logs. It simply processes the structured usage data that your system sends. Because events contain both usage and context, the billing system can apply flexible pricing rules that depend on properties such as model, feature, or environment.
Aggregation and rating
When usage events finally enter the system, Flexprice starts processing them in two stages. First, it measures what happened, and then it determines how much exactly the usage should cost.
Then the system groups them over defined time windows and applies pricing rules based on your product catalog.
Aggregation
Aggregation answers a simple question: how much usage happened during a given billing period.
Here, Flexprice collects all incoming events and summarizes them across a defined time window, such as hourly, daily, or monthly. The goal here is to calculate usage quantities before any pricing is applied to them.
Total tokens per customer
The system groups all token events by customer or tenant and calculates the total tokens consumed during the billing window.
Tokens grouped by model or feature
Usage can also be grouped by attributes like model name or product feature. This makes it possible to see which models or capabilities generate the most consumption.
Combined or derived metrics
Input and output tokens can be combined to calculate total tokens. Other derived metrics can also be computed depending on how usage is structured.
At this stage, the system is only measuring usage. Aggregation determines quantities but does not assign any monetary value.
Rating
Rating answers your next question: what should that usage actually cost?
After usage is aggregated, Flexprice applies the pricing rules defined in your product catalog. These rules convert usage quantities into charges or credit deductions.
Fixed price per 1,000 tokens
A simple rate where each block of tokens has a consistent price regardless of volume.
Tiered or volume-based pricing
The price per token can change as usage grows, allowing discounts at higher consumption levels.
Different prices for input and output tokens
Some products price input tokens and output tokens differently to reflect underlying provider costs.
Customer-specific overrides
Enterprise contracts can override standard pricing for specific customers or negotiated deals.
Model-based pricing
Usage from different models can be priced separately since model costs often vary significantly.
Rating converts usage quantities into actual billing outcomes. This results in monetary charges, credit deductions from a wallet balance, or a combination of both. Aggregation measures how much usage happened. Rating determines what that usage is worth.
Credits and wallet integration
Once usage has been rated, the system knows the monetary value of that consumption. The next question in line is how that value should be settled. This is where credit wallets come into the picture. Pricing determines how much something costs, while the wallet determines how that cost is paid.
A credit wallet acts as a balance that usage charges can draw from. Instead of billing only at the end of the month, customers can prepay and consume credits as they use the product.
Customers can prepay for token credits
Organizations can add funds to their wallet in advance. These funds represent credits that will be used to pay for future token usage.
Rated usage deducts from the wallet balance
When token events are rated and converted into charges, the corresponding value is deducted from the customer’s wallet balance.
Automated balance management rules
You can configure behaviors such as automatic top-ups, credit expiration rules, or minimum balance alerts to prevent usage interruptions.
Wallet balances update as rated usage is processed. Depending on how billing is configured, invoices can still be generated separately for reporting, reconciliation, or enterprise billing workflows.
Flexibility for AI and LLM pricing patterns
In the current scenario, AI products rarely follow a single and simple pricing structure. Different models have different costs. Some features consume far more tokens than others. Pricing often needs to reflect these differences while remaining understandable for customers.
Flexprice pricing logic can reference properties inside usage events; it becomes possible to build pricing models that match how LLM systems actually behave.
Different rates for different model families
Usage from one model can be priced differently from another, which helps maintain margins when model costs vary.
Hybrid subscription and usage pricing
A base subscription can provide platform access while token consumption is billed as variable usage on top.
Model or feature-based pricing
Pricing rules can reference attributes such as model name, feature type, or request category. This allows different rates to apply depending on which model or capability generated the usage.
This flexibility allows companies to price based on real token consumption while still aligning their pricing with upstream model costs.
Integration with billing, invoices, and external systems
After usage has been aggregated and rated, the resulting charges become part of the customer’s billing record. These charges are then included in the billing invoice workflow according to the subscription or contract configuration.
The billing system handles the logic that connects usage, pricing, and invoicing.
Charges attach to the subscription record
Rated usage is recorded against the customer’s subscription or billing account.
Invoices are generated on the billing schedule
Charges are included in invoices that follow the configured billing cycle, such as monthly or quarterly.
External payment systems execute payments
External payment processors such as Stripe, Razorpay, or other integrations can handle payment collection once invoices are issued.
Flexprice manages the billing logic that turns usage into charges. Payment providers handle the transaction side of collecting funds.
Common mistakes to avoid when metering LLM tokens
One thing you would have understood by now is that, as you start metering tokens.
The basic feels straightforward, like count usage, then store it, and after that bill on it. But one thing you miss out is that problems show up later.
Here are some common mistakes you should avoid while metering LLM tokens:
Only metering output tokens
It is tempting to track just the completion tokens because they feel like the visible output. But providers charge for both input and output.
Providers bill for input plus output tokens
System prompts and RAG context inflate input cost quickly
Billing only output leads to a silent margin loss
Always track input_tokens, output_tokens, and total_tokens
If you ignore input tokens, your costs rise quietly while your revenue stays flat.
Sending aggregated monthly totals
Some teams send a single number at the end of the month. It may look clean to you, but it is the main reason behind long-term rigidity.
Monthly totals remove model-level pricing flexibility
You lose feature-level breakdowns
No real-time wallet deduction or debugging clarity
Send granular usage events and aggregate later
When you only send 4.2 million tokens as a lump sum, you cannot answer basic questions about where that usage came from.
Not tagging the model in usage events
Models are not interchangeable from a pricing perspective. Costs may vary, and they often change.
Different models have different cost structures
Model pricing changes frequently
Without metadata, you cannot adjust pricing later
Always include model, feature, customer_id, and environment
If you skip metadata today, future pricing updates become painful migrations instead of simple config changes.
Ignoring retries and failed calls
Agents retry more than most teams expect. Especially under load or with tool failures.
You may pay for three attempts, but be billed for one success
Retries quietly shrink margins
Failed calls still consume tokens
You do not need to overcomplicate this. Just make sure retries are tracked intentionally, and it should not be ignored.
Treating one user request as one model call
In simple apps, one request maps to one model call. In agent systems, that assumption breaks fast.
Agent workflows chain multiple LLM calls
Tool calls and reasoning steps multiply tokens
Billing per request often underestimates the true cost
If your model is one request equals one call, your billing model will drift from reality as your product becomes more autonomous.
Wrapping up
LLM tokens start as a technical metric, but once you ship an AI product, they quickly become the unit that connects model usage, infrastructure cost, and revenue.
Without proper metering, token consumption grows quietly in the background while pricing and billing struggle to keep up.
The solution is not just counting tokens. It’s building a pipeline where token usage is captured as events, attributed to the right customer or feature, and routed into a billing system that can aggregate, rate, and charge for it reliably.
That’s where tools like Flexprice come in. Instead of stitching together logs, batch jobs, and spreadsheets, you can treat tokens as a first-class billing metric.
If you’re building an AI product where token consumption drives cost and value, getting token metering right early will save you from painful reconciliation later. The best time to build that foundation is before usage scales and billing becomes the bottleneck.
How can I measure token consumption and enforce quotas to control AI operational costs?
How can we meter inference requests at the user and tenant level to enable precise billing for an AI-as-a-service platform?
What is the difference between token-based pricing and per-seat pricing for AI products?
How do credit-based pricing models work for AI and LLM products?
Why should I meter both input and output tokens instead of just tracking completions?