Aanchal Parmar
Product Marketing Manager, Flexprice

Community pulse: what developers are saying
1. gpt-oss-20B
Runs well on consumer hardware (16 GB+ VRAM) “40 tokens/s on my RTX card, totally usable.”
Great for local-first workflows, but logic reasoning is weak without fine-tuning (failed classic puzzle tests, low accuracy on 11+ exam).
Non-English performance is hit-or-miss; some report slower outputs in early builds.
Benchmarks can vary. Some bloggers compare it to o3-mini, others say results depend heavily on prompt engineering.
2. gpt-oss-120B
Strong instruction following and coding capabilities: “best I’ve run locally for writing clean code.”
Can hit 30–35 tokens/s on a single 80 GB GPU; some even run CPU-only demos on high-RAM machines.
Mixed benchmark reception, certain threads show modest Simple-Bench scores (~22%), while others argue its MoE (Mixture-of-Experts) design makes it efficient for the scale.
Analysts frame it as near-parity to o4-mini on core reasoning while being deployable on a single high-end GPU
20B | Ideal Use Case | Watch-Outs |
|---|---|---|
20B | Teams wanting a fast, locally-hostable model for experimentation, chatbots, summarization, or lightweight reasoning tasks. | Reasoning accuracy is noticeably lower than leading frontier models (e.g., GPT-4, Claude 3 Opus); multilingual outputs can be inconsistent without fine-tuning. |
120B | Teams with 80 GB+ GPUs looking for strong instruction following, solid coding assistance, and faster inference speeds than dense models of similar size. | High hardware requirements; benchmark scores vary widely, so test on your own workloads before committing to production. |
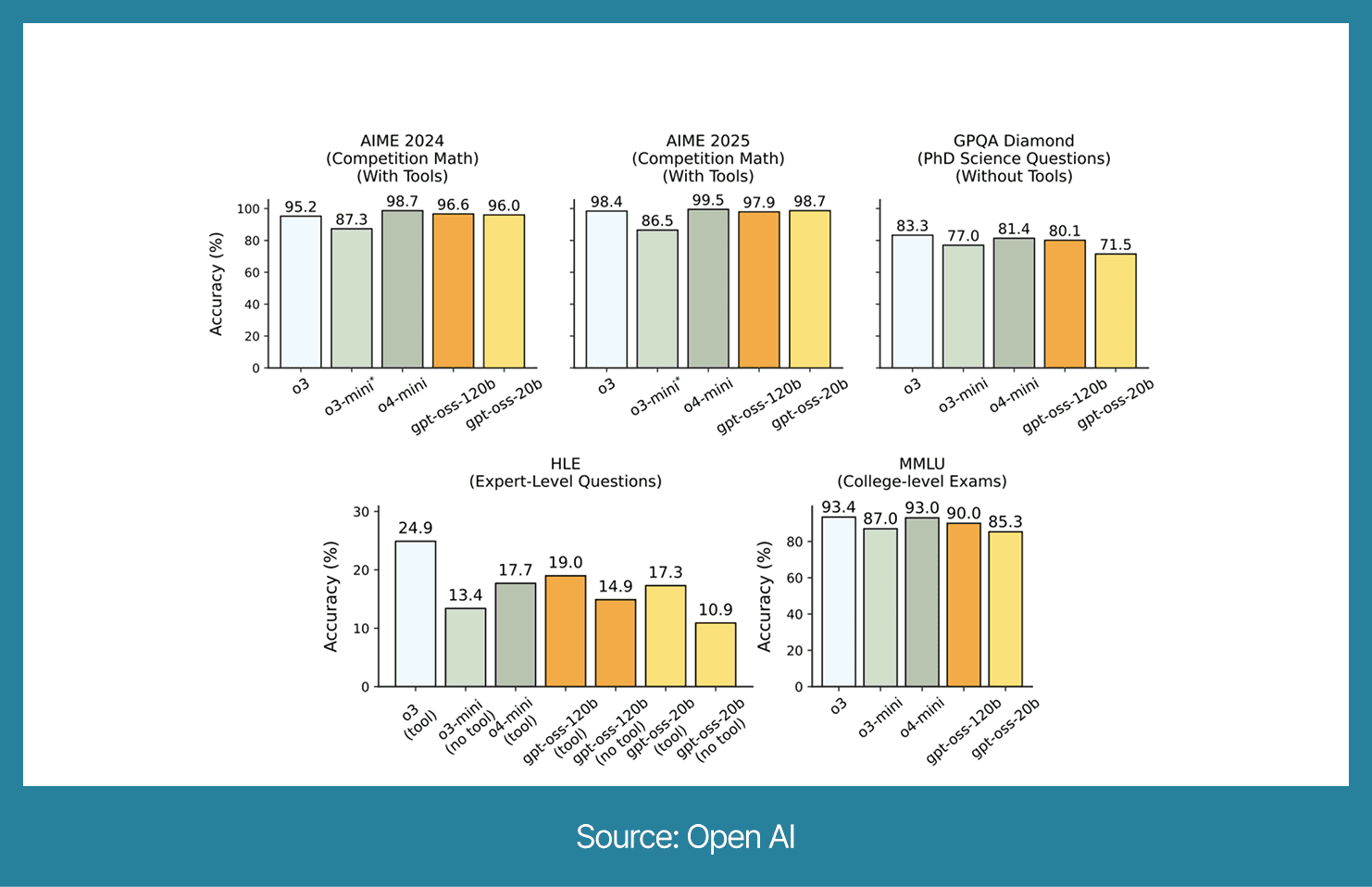
Key Features & Benchmark Highlights
Benchmark Comparisons: How gpt-oss Stacks Up
gpt-oss-120B
Reasoning & Coding: Matches or beats o4-mini; competitive with larger dense models.
HealthBench: Close to o3; outperforms GPT-4o in multiple categories.
SWE-bench Verified: 62.4% (GLM-4.5 scores 64.2%).
MMLU-Pro & AIME: Strong performance, ahead of many full-parameter models in this size class.
Strengths: Balanced across reasoning, coding, and domain-specific tasks; efficient for size due to MoE.
Limitations: Requires 80 GB+ GPU for optimal speed; benchmark gains may not translate 1:1 to all workloads.
gpt-oss-20B
Overall Performance: Comparable to o3-mini in many standard benchmarks.
Specialty Tasks: Excels in competition math and health-related reasoning.
Logic Testing: Low accuracy on UK 11+ exam (9/80 correct) without tuning.
Knowledge QA: Weak SimpleQA score, improves significantly with better prompts.
Strengths: Runs well on consumer-grade GPUs (16 GB VRAM+); ideal for local-first projects.
Limitations: Lower raw reasoning power vs. top-tier models; multilingual output inconsistent.
Key Architectural Features
Mixture-of-Experts (MoE) design: Only a subset of the total parameters is active at any given time, reducing compute cost while retaining capability.
128k token context window: Allows for very long conversations, large document processing, or multi-step reasoning chains.
Quantization options: Pre-quantized 4-bit and 8-bit weights for lower VRAM usage without a big performance hit.
Optimized attention mechanisms: Techniques like grouped query attention improve speed and efficiency for large context handling.
Analogy for Benchmarks
Think of the benchmarks like testing a car:
AIME/HealthBench scores = Top speed (peak reasoning ability)
Context window = Fuel tank size (how long it can handle complex input without running out of context)
MoE efficiency = Fuel efficiency (how much compute is needed for each “trip” of reasoning)
Reality Check
Benchmarks are controlled conditions, real-world workloads can vary.
20B may fall short on multi-step reasoning or nuanced logic without tuning
120B offers higher accuracy and more robust performance, but demands high-end GPUs (80 GB+ for optimal speed)
Business value for AI and Agentic companies
OpenAI’s gpt-oss-20B and gpt-oss-120B aren’t just research curiosities; they create practical, measurable advantages for companies building AI-first products. The biggest shift is in control: cost, compliance, and customization now sit in your hands rather than behind an API paywall.
1. Cost efficiency
API vs. Self-Hosting: Running inference locally or in your own cloud can cut per-million-token costs by 30–70% depending on GPU availability and utilization
Example: A high-traffic chatbot processing 500M tokens/month could save thousands of dollars in API fees if inference moves in-house
20B advantage: Lower hardware footprint means faster ROI for smaller teams
120B advantage: Higher accuracy per token processed means fewer retries and corrections
2. Compliance & data control
Self-hosting means sensitive data never leaves your infrastructure
Meets stricter requirements for sectors like finance, healthcare, and government without complex vendor contracts
Open-weight Apache-2.0 licensing (with OpenAI usage policy) simplifies legal review vs. closed, API-bound services
3. Customization and fine-tuning
Both models can be fine-tuned for domain-specific language, terminology, or compliance filters
Custom embeddings and retrieval-augmented generation (RAG) pipelines can be integrated without third-party API constraint.
Bottom line: For AI and agentic companies, these models lower the unit economics of running advanced LLM features, improve compliance posture, and unlock pricing flexibility, without sacrificing core capability.
Deployment and compliance checklist
If you’re planning to deploy gpt-oss-20B or gpt-oss-120B in production, treating them like any other enterprise-grade software stack will save you time.
1. License & Policy Review
Apache-2.0 license: Permissive for both commercial and non-commercial use
OpenAI usage policy: Certain applications (e.g., generating misinformation) remain prohibited even with open weights
Action: Get legal confirmation that your intended use aligns with both
2. Hardware Requirements
gpt-oss-20B: Runs on GPUs with ≥16 GB VRAM; suitable for a single workstation or small cloud instance
gpt-oss-120B: Requires an 80 GB GPU or multi-GPU setup for real-time performance
Action: Decide between local deployment, cloud GPUs, or hybrid infrastructure
3. Data Residency & Privacy
Ensure all processing happens in approved geographic regions for compliance (e.g., GDPR, HIPAA)
For sensitive data, deploy in a private VPC or on-prem hardware
4. Observability & Monitoring
Log prompt/response pairs for auditing
Track token usage, latency, and failure rates
Set alerts for unusual activity (e.g., rapid token spikes from one client)
5. Security Hardening
Isolate model servers from public networks
Use API gateways or auth layers for access control
Regularly patch hosting environment and supporting libraries
Wrapping up
OpenAI’s gpt-oss release signals a broader shift, one where high-performance models aren’t locked behind API gates but can be run, adapted, and monetized on your own terms. The move also sets a precedent: after years of partial openness, OpenAI has now shown it’s willing to bring frontier-adjacent capability into the public domain.
Looking ahead, expect three trends:
Multimodal open weights, future releases may integrate text, image, and audio processing in a single package.
Specialized domain variants, healthcare, finance, and legal-tuned versions optimized for compliance-heavy industries.
Ecosystem tools, better fine-tuning kits, quantization methods, and observability frameworks to accelerate real-world adoption.
For AI-first companies, this is a moment to test and embed these models into workflows before the next release cycle reshapes the playing field.
The first movers here will gain not just cost and control advantages, but also the credibility that comes from delivering cutting-edge AI without reliance on opaque third-party infrastructure.